

How do SSDs work?
Solid State Drives (SSDs) are undoubtedly a marvel of modern technology. We trust SSDs every day to store our valuable data and often don’t think twice about the possibility of the SSD failing and losing this data. As marvellous as these SSDs are, we don’t pay enough attention to what happens “under the hood”, and simply allow the magic of modern technology to do its thing. So this begs several questions: what is happening under the hood? How does my SSD store my data? Will or when will my SSD fail? What can I do to stop it failing? And what do I do when it fails? In this blog post, we aim to answer these questions and more!
Background and SSD history
The first consumer SSD that we might recognise today was first introduced in 1991 by SanDisk. Solid state storage was available before this, as early as the 1970s. However, these often used volatile RAM chips, meaning that hard disk drives (HDDs) were required to store the data from the RAM chips when the power was removed. Check out this blog post to find out more about how HDDs work.
What is happening under the hood?
Before we tackle the later questions, let’s answer: what is happening under the hood? SSDs are fundamentally made up of two parts (at least for now): the storage and the controller. The storage part of the SSD uses NAND flash cells to store data persistently. The controller of the SSD is an embedded processor that executes firmware and enables communication between the SSD and the host interface. The host interface connects the SSD and the host computer, and makes use of predefined protocols like SATA or NVMe to facilitate communication between the computer and the SSD. We can essentially think of the controller as managing the physical storage of data.
First, we’ll look in more detail at the storage part of the SSD and the NAND flash cells. A NAND cell consists of Floating Gate Transistors (FGT). When discussing transistors, we first have to discuss what they are made of, as this directly impacts how they function. Transistors are made of semiconductor materials, most commonly silicon. A semiconductor is a material that conducts electricity better than an insulator, like the PVC you find insulating wires, but worse than a conductor, like the copper you find conducting electricity inside the insulated wire.
We can think of conductivity as the ability for electrons to move between atoms. The conductivity of the atom depends on the number of electrons in the valence (the outermost) shell. The lower the number of electrons in the valence shell the better the conductivity; the higher the number of electrons in the valence shell, the worse the conductivity. If you have ever wondered why copper is such a good conductor, it’s because it has one electron in its valence shell. Silicon has four valence electrons, making it a worse conductor than copper.
The really great thing about semiconductors like silicon, is that their conductive properties can be changed by intentionally introducing impurities, this is called doping. By introducing materials with more valence electrons (n-doping) or less valence electrons (p-doping), we can change the conductive property of the semiconductor.
A common impurity used for n-doping is phosphorus. Phosphorus has 5 valence electrons, meaning that once the phosphorus has been added to the silicon structure, one electron remains unbonded with the surrounding silicon atoms and is free to move, allowing an electric current to flow, the impurity in this instance is known as the donor, due to it donating an electron. It is known as n-doping due to the higher number of negatively charged electrons moving through the structure.
P-doping works in the opposite way. When a semiconductor is p-doped, it is treated with a material that has 3 valence electrons, commonly boron. This is known as the acceptor, due to it taking on an electron from the silicon. Once boron has been added to the silicon structure, a ‘hole’ is created in the electrons of the silicon structure, the electrons can then move from the valence shell of the silicon into the hole in the valence shell of the boron. We can think of these holes moving in the opposite direction to the flow of electrons. Due to the hole lacking an electron, it acts as a positive charge attracting electrons, giving p-type doping its name.
Transistors are made with both n-doped and p-doped semiconductors. The transistor is made up of three parts: the source, the drain, and the gate. Commonly the source and drain are made of n-doped semiconductor, separated by p-doped semiconductor.
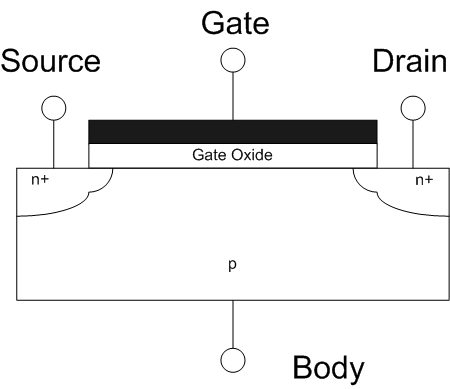
A ‘depletion’ layer is formed between the p-type and n-type semiconductors. The depletion layer occurs when the extra electrons from the n-type semiconductor fill the holes in the p-type semiconductor. These extra electrons give the depletion layer of p-type semiconductor a negative charge, acting as a barrier to any more electrons flowing from the source to the drain. The gate is separated from the p-doped semiconductor by a dielectric oxide. By manipulating the charge on the gate, we can create an electric field that enables electrons to flow from the source to the drain. This electric field is what gives the field effect transistor its name.
A FGT builds on this idea by adding another gate between the existing gate and the electrons beneath. This gate is completely electronically isolated, with a dielectric oxide layer between itself and the electrons, and between itself and the existing gate (in an FGT the existing gate is called the control gate). Since the new gate we have added is completely isolated, it is called the floating gate and is where the transistor gets its name. The oxide layer separating the floating gate and the electrons is thinner than the oxide layer separating the control gate and the floating gate. By applying a charge to the control gate, similar to applying a charge to a gate in a MOSFET, some electrons are able to move (this is known as tunneling, we will come back to this later) through the thinner oxide layer and reside in the floating gate. When the charge on the control gate is removed, these electrons are trapped in the floating gate, leaving the gate with an electrical charge. This occurs every time a cell is programmed. To remove the charge from the cell, a positive voltage is applied to the source and drain, while a negative voltage is applied to the control gate, allowing the electrons to move out of the floating gate. By measuring the threshold voltage of the floating gate, we can determine whether the cell has been programmed or not, allowing us to represent a bit (1 or 0). The table below shows the relationship between the threshold voltage of the cell and the bit value the cell represents:
| Threshold voltage | Bit Value |
|---|---|
| 0V - 3V | 1 |
| 3V - 6V | 0 |
We can think of 0V to 3V and 3V to 6V being relatively arbitrarily chosen reference points to distinguish between the bit values.By adding more reference points, we can make the cell represent more than one bit at a time:
| Threshold Voltage | Bit Value |
|---|---|
| 0V - 1.5V | 11 |
| 1.5V - 3V | 01 |
| 3V - 4.5V | 10 |
| 4.5V - 6V | 00 |
By setting the threshold voltage to one of the four predefined levels, we can make the cell represent two bits. When the cell represents one bit at a time it is called a Single Level Cell (SLC). When the cell represents two bits at a time, it is called a Multi Level Cell (MLC). This principle can continue to make the cell represent more and more bits at the same time: Triple Level Cell (TLC), Quad Level Cell (QLC), etc. This is called bit density. Generally, SLC SSDs are reserved for enterprise usage, while MLC is marketed as the premium consumer SSD. The higher the bit density, the lower the cost of the SSD, however, the performance and lifespan of the SSD is also decreased when compared to SSDs with a lower bit density. We now have the basics for how a NAND cell works, and how the NAND cell can be used to represent multiple bits at once.
Layers of NAND flash cells can then be stacked on top of each other, this is known as 3D NAND. By layering the flash cells vertically, SSD manufacturers can fit more flash cells in the same sized SSD. This enables larger amounts of storage in the same physical package. As noted by ATP inc, 3D NAND’s benefits also expand far beyond storage capacity:
“3D NAND also consumes less power; yields lower cost per gigabyte; generates faster read/write by using simpler algorithms; and delivers better reliability, endurance and overall performance by reducing cell-to-cell program interference”
It is important to also note that we are seeing the replacement of homogeneous storage, SSDs made up of cells that all have the same bit density, with heterogeneous storage, SSDs that contain cells with different bit densities. For example, this would allow for SLC storage for data that changes frequently, and QLC for data that changes less frequently in the same SSD. This would allow us to make the most of the strengths of each type of cell. It is interesting to note that this does present certain challenges for file systems that sit on top of heterogeneous storage, we discuss this in more detail in this blog post.
Next, it is important to clarify what we mean by ‘move’ electrons. Moving electrons through the dielectric barrier is more accurately described as ‘tunneling’; there are two methods for this: Fowler-Nordheim Tunneling and Hot-Carrier Injection. It is not necessary for us to understand the ins and outs of tunneling, however, it is important to understand that both methods of tunneling are responsible for moving electrons through a dielectric oxide only when there is a sufficient electric field. This ensures that when the charge is removed from the cell, the electrons are not able to move back out of the floating gate.
You can read more detailed information and figures about Fowler-Nordheim Tunneling and Hot Carrier Injection, courtesy of ScienceDirect.
The SSD Controller is an embedded processor that executes firmware, records S.M.A.R.T data, performs wear leveling, storage addressing, caching and security functions like hardware level encryption. The controller lives up to its name: controlling the SSD, it also interfaces with the host computer ensuring that data can be written and read. The controller communicates with the host computer via the ‘host interface’. This is a protocol or set of protocols that define how data is transferred between the host and the SSD. We touch more on the different host interfaces SSDs use in this blog post. When describing hardware, people will often refer to the Central Processing Unit (CPU) as being the brain of the computer, we can essentially think of the controller as being the brain of the SSD.
We now have an understanding of how SSDs store data in cells and the purpose of the drive’s controller, but how are the cells organized and how does the controller manage them? Groups of cells are organized into pages, often made up of 4KB of storage but can also be larger than this. Groups of pages are then organized into blocks, commonly 128 pages are combined into a block. Therefore, a block made up of 4KB pages contains 512KB of storage. A block is the smallest unit of storage that can be erased/programmed by the controller. Flash cells can only be written to when they are empty and do not support rewrites, leading to a phenomenon known as write amplification. This is an undesirable phenomenon that leads to a larger number of physical writes taking place to the disk than the number of logical writes from the host. Since a block is the smallest unit of storage that the controller can erase/program, if a single page is edited, the entire block it is located in must be erased and then reprogrammed with the block containing the modified data. This results in a process called the read-erase-modify-write cycle. The contents of the block are read and stored in the SSD’s cache, the block is then erased, the edited page is then written to the block that is stored in the cache, and then the edited block that is stored in the cache can be written back to the empty block. This increases the number of erase/program cycles when data is modified.
The SSD is addressed by the host using Logical Block Address (LBA). LBA assigns each block on the SSD a storage number starting at 0. The SSD’s controller is then responsible for mapping these logical addresses to physical locations on the drive. To do this, many SSDs use a DRAM (Dynamic Random Access Memory) cache to map data. This fast DRAM cache allows data to be rapidly located and then accessed. Since the DRAM is volatile, the SSD controller is responsible for moving data in and out of the cache.
How does an SSD fail?
We now know how SSDs work and this may give you some idea of their points of failure. This is where tunneling comes back in. Tunneling electrons through the dielectric layer causes damage to the dielectric layer separating the floating gate and the channel, leading to Stress Induced Leakage Current (SILC). Damage to the dielectric oxide eventually means that the cell can no longer hold a sufficient charge to manipulate the threshold voltage of the cell, meaning that it cannot be reliably programmed or read.
Although we think of SSDs as being more robust than HDDs, and they are, they are still susceptible to physical damage. Damage to NAND flash cells can render them inoperable leading to bad blocks and potential data loss, while damage to the SSDs controller can prevent the SSD from functioning at all. As with all storage devices, damage to the SSD’s pins or the port that it is connected to can also prevent data from being reliably read from or written to the SSD.
What can I do to stop it failing?
Unfortunately, nothing. Although we don’t think of SSDs having moving parts, we can see from the information above that SSDs have billions of electrons tunneling in and out of MOSFETs. These electrons are essentially moving parts and unfortunately things that move eventually stop moving. However, there are things that you can do to extend the life of your SSD. As we have discussed above, erase and program operations (stress events) cause electrons to pass through a dielectric layer, weakening it. SSD manufacturers will often guarantee a minimum number of program/erase cycles that you can expect before a cell fails. Commonly quoted figures are 100,000 cycles for a SLC, and 10,000 for a MLC. The number of cycles expected per cell continues to decrease as the bit density increases. It is important to note that these are a minimum estimate of cycles based on performance while being stress tested. The number of cycles that the cells may endure in real world applications may be a lot higher or lower.
At first these numbers may not sound very high, however, it should be noted that these figures are for the individual blocks that make up the SSD and not the SSD as a whole. The SSD’s firmware implements some clever tricks to extend the lifespan of the SSD as long as possible. The first trick is wear leveling: this works by evenly distributing write operations across blocks on the SSD, to ensure that a disproportionate amount of wear does not occur for certain blocks. The two methods of wear leveling are dynamic wear leveling and static wear leveling. Dynamic wear leveling occurs when data is written directly to blocks that have a lower wear count than other cells on the drive. This is done by taking all the blocks in an erased state and comparing the erase count for each block. The block with the lowest erase count is written to first, then the block with the second lowest erase count, etc. Static wear leveling is similar to dynamic wear leveling, with the addition of static data blocks that are not being modified, also being moved from cells with a low erase count. This allows these blocks to be written to by other data that changes more frequently. Wear leveling is more effective when an amount of unused space is maintained on the drive, as there is a pool of unused blocks that can have their erase count compared, and then be written to. This is where the SSD’s second trick comes into play: overprovisioning. Overprovisioning essentially locks away a number of the SSD’s blocks for operations performed by the SSD controller e.g. garbage collection, bad block management, and wear leveling. Overprovisioning essentially gives the SSD controller extra NAND flash cells that it can use as necessary to ensure smooth operation of the SSD.
This is all done behind the scenes by the SSD so back to the original question, what can I do to stop it failing? There are several steps that you can also perform to increase the lifespan of your SSD. The first is to have periods where the SSD is inactive. Research has shown that allowing for a “recovery period” between P/E cycles can massively increase the endurance of the drive by detrapping electrons that have become trapped in the oxide layer. I recommend reading the paper here for more detailed information about their findings. Temperature management of the SSD is also important. Generally it is recommended that the operating temperature of the SSD remains between 0 and 70 degrees celsius. Studies have shown that the recovery period can be effective at temperatures as low as 25 degrees celsius. It is important to consult the manufacturer’s documentation for more information about the desired conditions for the drive.
Due to SSDs having a maximum number of read/write cycles, it is important to ensure that unnecessary read/write cycles do not occur. The most common mistake that people make is to defragment their SSD. Fragmentation occurs when related data is not written to contiguous sectors, and is instead spread out across the storage media. This presents a problem for magnetic storage with moving parts, like a hard disk drive, as it takes time for the read/write head to move from one sector to another. As a result HDDs have substantially better performance for sequential I/O than random I/O. Data fragmentation means that the HDD will be performing random I/O more frequently. In contrast to a hard disk drive, an SSD has no moving parts, meaning that random I/O is not much slower than sequential I/O, as a result fragmentation does not present a large problem for SSDs. This is further compounded by the fact that SSDs frequently move data around internally anyway as part of wear leveling.
How long will my SSD last?
This is a difficult question to answer. As we have seen, SSDs are generally limited by the amount of program/erase cycles that they can perform, so the rather ambiguous answer is: “it depends!” It depends on how many program/erase cycles the manufacturer has said the drive can perform, it depends on how rapidly you are performing program/erase cycles, and as we have discussed, it can also depend on the amount of time between these program/erase cycles. Unfortunately, there is no real definitive answer. The S.M.A.R.T tools that come with the drive should be monitored to view the health of the drive. This can provide more information about how many program/erase cycles the SSD has performed and the SSD’s general health. S.M.A.R.T tools are the best tools we have to monitor our SSDs and give the most accurate answer to the question ‘how long will my SSD last’?
Although we have provided steps that will improve the lifespan of your SSD, the SSD will still eventually fail and as we discussed earlier it can occur suddenly. It is always recommended that the data on your drives is regularly backed up, this will ensure that in the event of an SSD failure, your data is not lost and can be restored to a new drive.
What do I do when my SSD fails?
If the drive that has failed is being used to store user data, then the images you have created of the drive can be restored to a new drive using Macrium Reflect within Windows. This KB article contains the steps to do this.
If the SSD that has failed contains your system partitions (OS partitions), then you will no longer be able to boot Windows, meaning that the image cannot be restored using Macrium Reflect installed in Windows. In this case, the image will need to be restored to a new SSD using the Macrium Reflect rescue media. This KB article contains the steps to restore an image using the rescue media. It is important that you have a rescue media created and tested, this will ensure that recovery can be easily performed in the event that Windows is no longer bootable. We strongly recommend that you create your rescue media by following the steps in this KB article if you have not done so already.

How to Reduce the Cost of Running a NAS
World Backup Day 2022

